负载均衡是什么? 负载均衡(Load Balance),意思是将负载(如前端的访问请求)进行平衡、(通过负载均衡算法)分摊到多个操作单元(服务器,中间件)上进行执行。是解决高性能,单点故障(高可用),扩展性(水平伸缩)的终极解决方案。可以理解为,负载均衡是高可用和高并发共同使用的一种技术。
负载均衡的作用:
1、增加吞吐量,解决并发压力(高性能);
2、提供故障转移(高可用);
3、通过添加或减少服务器数量,提供网站伸缩性(扩展性);
4、安全防护(负载均衡设备上做一些过滤,黑白名单等处理)。
常见负载均衡软件 Nginx rr:轮叫,轮流分配到后端服务器;
Dubbo 支持4种算法(随机、轮询、活跃度、Hash一致性),而且算法里面引入权重的概念。
SpringCloud Feign 支持很多种算法,包括:轮询、随机、最小连接、区域加权、重试以及ResponseTime加权。也可以自己实现负载均衡算法
负载均衡算法是什么? 负载均衡服务器在决定将请求转发到具体哪台真实服务器时,是通过负载均衡算法来实现的。负载均衡算法可以分为两类:静态负载均衡算法和动态负载均衡算法。
静态负载均衡算法包括:轮询、比率、优先权等 比率(Ratio)
优先权(Priority)
1、轮询法 轮询(Round Robin):顺序循环将请求一次顺序循环地连接每个服务器。以轮询的方式依次请求调度不同的服务器;实现时,一般为服务器带上权重。
优点:服务器请求数目相同;实现简单、高效;易水平扩展。
缺点:服务器压力不一样,不适合服务器配置不同的情况;请求到目的结点的不确定,造成其无法适用于有写操作的场景。
应用场景:数据库或应用服务层中只有读的场景。
2、随机法 将请求随机分配到各个节点。由概率统计理论得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配,也就是轮询的结果。
优缺点和轮询相似。
3、源地址哈希法 源地址哈希的思想是根据客户端的IP地址,通过哈希函数计算得到一个数值,用该数值对服务器节点数进行取模,得到的结果便是要访问节点序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会落到到同一台服务器进行访问。
优点:相同的IP每次落在同一个节点,可以人为干预客户端请求方向,例如灰度发布;
缺点:如果某个节点出现故障,会导致这个节点上的客户端无法使用,无法保证高可用。当某一用户成为热点用户,那么会有巨大的流量涌向这个节点,导致冷热分布不均衡,无法有效利用起集群的性能。所以当热点事件出现时,一般会将源地址哈希法切换成轮询法。
4、加权轮询法 不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
加权轮询算法要生成一个服务器序列,该序列中包含n个服务器。n是所有服务器的权重之和。在该序列中,每个服务器的出现的次数,等于其权重值。并且,生成的序列中,服务器的分布应该尽可能的均匀。比如序列{a, a, a, a, a, b, c}中,前五个请求都会分配给服务器a,这就是一种不均匀的分配方法,更好的序列应该是:{a, a, b, a, c, a, a}。
优点:可以将不同机器的性能问题纳入到考量范围,集群性能最优最大化;
缺点:生产环境复杂多变,服务器抗压能力也无法精确估算,静态算法导致无法实时动态调整节点权重,只能粗糙优化。
5、加权随机法 与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
6、键值范围法 根据键的范围进行负债,比如0到10万的用户请求走第一个节点服务器,10万到20万的用户请求走第二个节点服务器……以此类推。
优点:容易水平扩展,随着用户量增加,可以增加节点而不影响旧数据;
缺点:容易负债不均衡,比如新注册的用户活跃度高,旧用户活跃度低,那么压力就全在新增的服务节点上,旧服务节点性能浪费。而且也容易单点故障,无法满足高可用。
动态负载均衡算法包括:最少连接数、最快响应速度、观察方法、预测法、动态性能分配、动态服务器补充、服务质量、服务类型、规则模式等
最少连接
优点:根据服务器当前的请求处理情况,动态分配;
缺点:算法实现相对复杂,需要监控服务器请求连接数;
最快模式(Fastest)
观察模式(Observed)
预测模式(Predictive)
动态性能分配(Dynamic Ratio-APM)
动态服务器补充(Dynamic Server Act)
服务质量(QoS)
服务类型(ToS)
规则模式
1、最小连接数法 根据每个节点当前的连接情况,动态地选取其中当前积压连接数最少的一个节点处理当前请求,尽可能地提高后端服务的利用效率,将请求合理地分流到每一台服务器。俗称闲的人不能闲着,大家一起动起来。
优点:动态,根据节点状况实时变化;
缺点:提高了复杂度,每次连接断开需要进行计数;
实现:将连接数的倒数当权重值。
2、最快响应速度法 根据请求的响应时间,来动态调整每个节点的权重,将响应速度快的服务节点分配更多的请求,响应速度慢的服务节点分配更少的请求,俗称能者多劳,扶贫救弱。
优点:动态,实时变化,控制的粒度更细,跟灵敏;
缺点:复杂度更高,每次需要计算请求的响应速度;
实现:可以根据响应时间进行打分,计算权重。
3、观察模式法 观察者模式是综合了最小连接数和最快响应度,同时考量这两个指标数,进行一个权重的分配。
手写随机算法 随机算法和随机加权算法是比较简单的,接下来我们用代码实现一下
完全随机算法 首先我们把服务器ip储存下来,再调用random就可以随机获得一个服务器ip
1 2 3 4 5 6 7 8 public class ServerIps public static final List<String> LIST = Arrays.asList("A" ,"B" ,"C"
随机的方法
1 2 3 4 5 6 7 8 public class RandomSelect public static String getServer () new Random();int rand = random.nextInt(ServerIps.LIST.size());return ServerIps.LIST.get(rand);
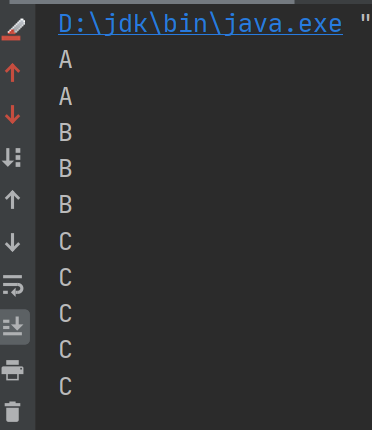
我们用一个测试类来测试随机算法,size越大的话,测出来的数据也就也越接近真实情况
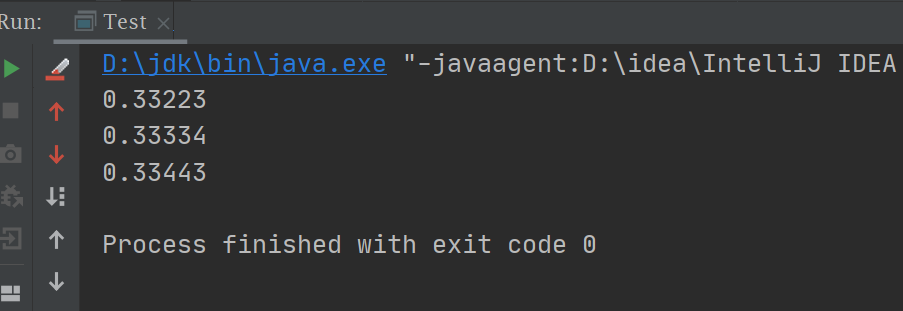
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Test public static void main (String[] args) double a = 0 , b = 0 , c = 0 ;int size = 100000 ;"" ;for (int i = 0 ; i < size; i++) {if (ip.equals("A" )) {if (ip.equals("B" )) {if (ip.equals("C" )) {"\n" + b / size + "\n" + c / size + "" );
可以看到结果很接近1:1:1 ,比较符合我们的结论: 将请求随机分配到各个节点。由概率统计理论得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配,也就是轮询的结果。
加权随机算法 由于访问概率大致相同,所以如果部分服务器性能不一致的话,容易导致性能差的服务器压力过大,所以要根据服务器性能不一致的情况,给性能好的服务器多处理请求,给差的少分配请求(能者多劳)所以就需要在随机算法的基础上给每台服务器设置权重,延伸为加权随机算法
1、将应用服务器集群的IP存到Map里,每个IP对应有一个权重
接下来我们来实现一个加权随机算法,首先还是把我们的服务器储存一下
1 2 3 4 5 6 7 8 9 10 public static Map<String, Integer> map = new HashMap<String, Integer>() {"A" , 2 );"B" , 3 );"C" , 5 );
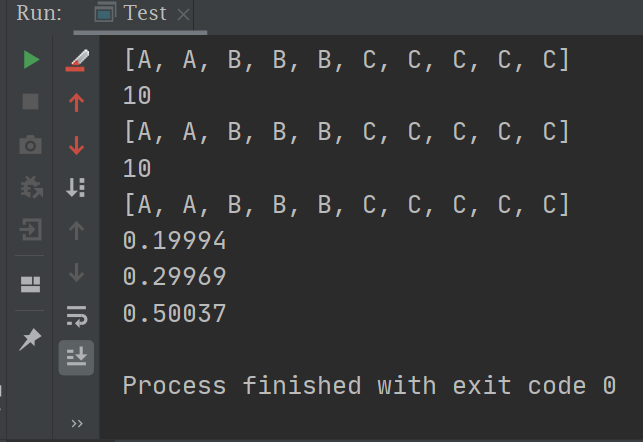
我们分配的权重 A:2 B:3 C:5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class RandomSelect2 public static String getServer () new ArrayList<String>();for (Map.Entry<String, Integer> item : map.entrySet()) {for (int i = 0 ; i < item.getValue(); i++) {int allWeight = map.values().stream().mapToInt(a -> a).sum();"" );int number = random.nextInt(allWeight);return ipList.get(number);
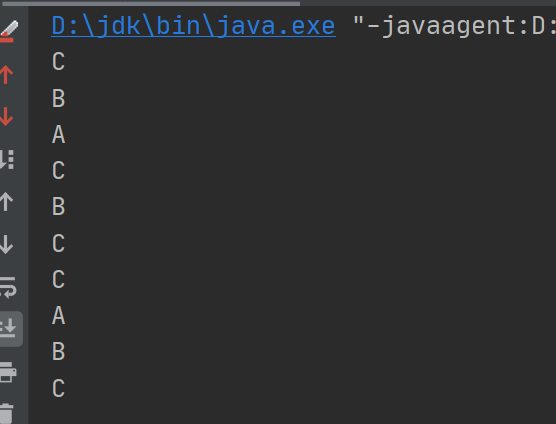
我们继续用测试类来测试随机加权算法,size越大的话,测出来的数据也就也越接近真实情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Test public static void main (String[] args) double a = 0 , b = 0 , c = 0 ;int size = 100000 ;"" ;for (int i = 0 ; i < size; i++) {if (ip.equals("A" )) {if (ip.equals("B" )) {if (ip.equals("C" )) {"\n" + b / size + "\n" + c / size + "" );
可以看到结果很接近 A:2 B:3 C:5 ,这就是随机加权算法啦 , 给性能好的服务器多处理请求,给差的少分配请求(能者多劳)
轮询算法 假设有 N 台服务器 S = {S0, S1, S2, …, Sn},算法可以描述为:
轮询算法与服务器权重没有关系,每个服务器有序的会被轮询到。
1 2 3 4 5 6 7 8 9 10 11 public class RoundRobin static int index = 0 ;public static String getServer () if (index == ServerIps.LIST.size()) {0 ;return ServerIps.LIST.get(index++);
用测试类来测试轮询算法,size越大的话,测出来的数据也就也越接近真实情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Test public static void main (String[] args) double a = 0 , b = 0 , c = 0 ;int size = 100000 ;"" ;for (int i = 0 ; i < size; i++) {if (ip.equals("A" )) {if (ip.equals("B" )) {if (ip.equals("C" )) {"\n" + b / size + "\n" + c / size + "" );
加权轮询算法 其实和加权随机本质上差不多,都是把按照权重去添加再从头到尾的遍历,代码如下
1 2 3 4 5 6 7 8 9 10 11 public class ServerIps public static final Map<String,Integer> WEIGHT_LIST = new LinkedHashMap<>();static {"A" ,2 );"B" ,3 );"C" ,5 );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class WeightRandom public static String getServer () new ArrayList<>();for (String ip : ServerIps.WEIGHT_LIST.keySet()){for (int i = 0 ;i < weight;i++){new Random();int randomPos = random.nextInt(ips.size());return ips.get(randomPos);
这个就不进行测试了 最后结果也是符合结论
下面有另外一种更高级的算法来实现加权轮询
实现加权轮询的优化
假设我们以10次请求来作为一个单位,我们可以发现,请求次数小于权重,就可以放到响应的区域里,比如0,权重小于2,我们就可以放到第一个位置,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ServerIps public static final List<String> LIST = Arrays.asList("A" ,"B" ,"C" public static final Map<String,Integer> WEIGHT_LIST = new LinkedHashMap<>();static {"A" ,2 );"B" ,3 );"C" ,5 );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class WeightRoundRobin public static String getServer (Integer num) int totalWeights = ServerIps.WEIGHT_LIST.values().stream().mapToInt(w -> w).sum();for (String ip:ServerIps.WEIGHT_LIST.keySet()){if (pos < weight){return ip;return "" ;public static void main (String[] args) for (int i = 0 ;i < 10 ;i++){
运行之后我们发现 轮询了2次A 3次B 5次C 但是这个加权轮询算法是有缺点的
平滑加权轮询 平滑加权轮询 会把轮询的请求打散 让每个服务器都比较均衡的获得请求 避免了同一个时刻大量请求打入,更加平衡
假设有 N 台服务器 S = {S0, S1, S2, …, Sn},默认权重为 W = {W0, W1, W2, …, Wn},当前权重为 CW = {CW0, CW1, CW2, …, CWn}。在该算法中有两个权重,默认权重表示服务器的原始权重,当前权重表示每次访问后重新计算的权重,当前权重的出初始值为默认权重值,当前权重值最大的服务器为 maxWeightServer,所有默认权重之和为 weightSum,服务器列表为 serverList,算法可以描述为:
固定权重为 2,3,5 动态权重第一次设置为 0,0,0
第二次 ,我们把上一次的动态权重加上我们的固定权重 得到新的权重 得到新的权重 4,6,0 当前最大权重是6 权重变化后 对应的服务器是B 返回一个B服务器,重复上一步骤,B的权重 减去总权重 得到新的动态权重 4,-4,0 以此类推10次 便会发现 动态权重又变回了 0,0,0
接下来我们来看看代码 ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class Weight private String ip;private Integer weight;private Integer currentWeight;public Weight (String ip, Integer weight, Integer currentWeight) this .ip = ip;this .weight = weight;this .currentWeight = currentWeight;public String getIp () return ip;public void setIp (String ip) this .ip = ip;public Integer getWeight () return weight;public void setWeight (Integer weight) this .weight = weight;public Integer getCurrentWeight () return currentWeight;public void setCurrentWeight (Integer currentWeight) this .currentWeight = currentWeight;
然后是算法的具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class WeightRoundRobin2 public static Map<String,Weight> currWeights = new HashMap<>();public static String getServer () int totalWeights = ServerIps.WEIGHT_LIST.values().stream().mapToInt(w -> w).sum();if (currWeights.isEmpty()) {new Weight(ip,weight,0 ));for (Weight weight: currWeights.values()) {null ;for (Weight weight: currWeights.values()) {if (maxCurrentWeight == null || weight.getCurrentWeight() > maxCurrentWeight.getCurrentWeight()) {return maxCurrentWeight.getIp();public static void main (String[] args) for (int i = 0 ; i < 10 ; i++) {
接下来我们看看测试代码,我们可以发现 轮询的请求已经被打散了 不会在同一个时刻不断的访问同一个服务器了,
一致性哈希环算法 一致性哈希算法在1997年由MIT的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题。
算法原理
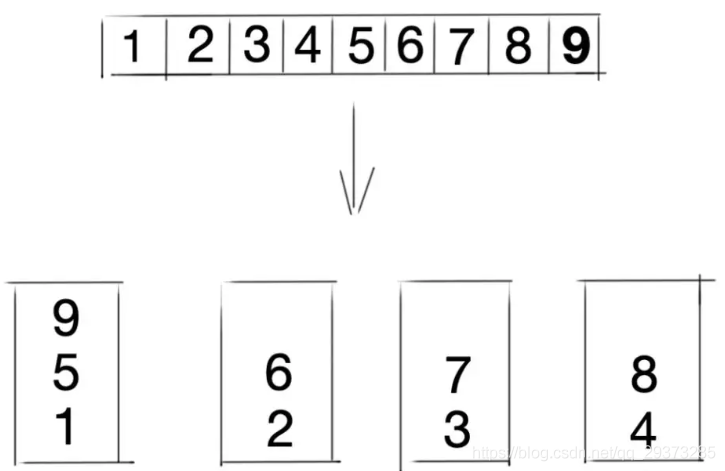
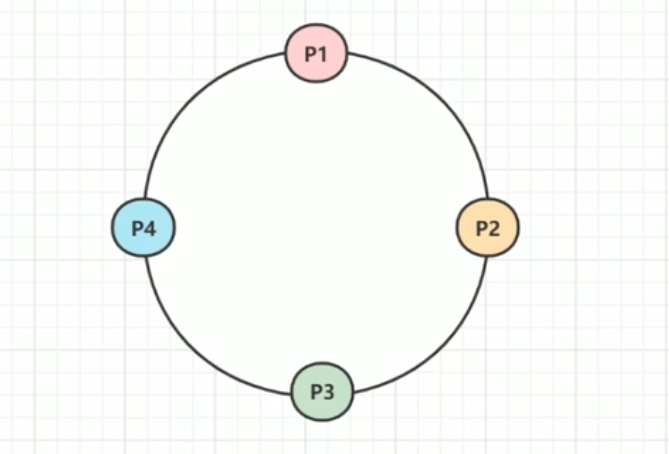
我们可以看到这里有一个环,环上面有4个哈希值,p1,p2,p3,p4 这四个哈希值对应四个服务器,用户可以访问其中的任何一台,我们通过哈希运算,把四个服务器的哈希值放到哈希环上去,这个哈希环是一个有序的哈希环 P1 < P2 < P3 < P4
优化
我们可以看到有一些椭圆形的节点,这些就是我们虚拟出来的节点,映射的虚拟节点越多,哈希环就会越散列,流量就会分散的越小,处理的请求也会变的很均匀
这就是一致性哈希环算法的一种变种
TreeMap的讲解 TreeMap是一种红黑树,我们可以依靠他的特点来完成一致性哈希环算法,那我们是如何用TreeMap来实现呢?
我们通过tailMap()这个方法可以得到大于某个值后面的所有值
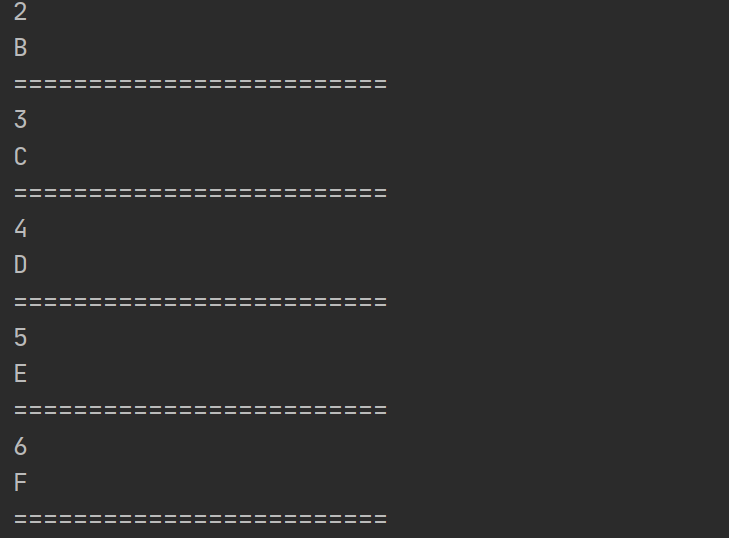
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 TreeMap<Integer,String> virtualNodes = new TreeMap<>();1 ,"A" );2 ,"B" );3 ,"C" );4 ,"D" );5 ,"E" );6 ,"F" );2 );for (Map.Entry<Integer,String> entry : sortedMap.entrySet()){"=========================" );
1 2 3 4 5 6 7 8 9 10 11 TreeMap<Integer,String> virtualNodes = new TreeMap<>();1 ,"A" );2 ,"B" );3 ,"C" );4 ,"D" );5 ,"E" );6 ,"F" );2 );
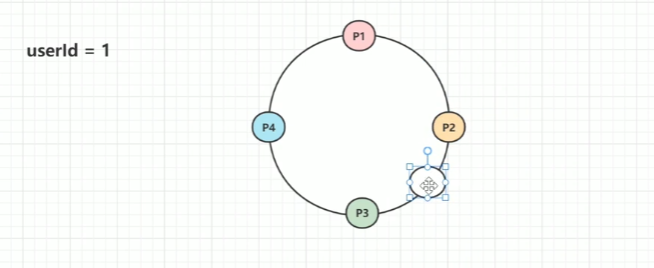
这里有个关键点提示,假如你寻找的值比整个环上最大的值都大,就放到比P4大的那一段上面去就好了,也就是返回P1就行了
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 public class ConsistentHash private static TreeMap<Integer,String> virtualNodes = new TreeMap();private static final int VIRTUAL_NODES = 160 ;static {for (String ip: ServerIps.LIST) {for (int i = 0 ; i < VIRTUAL_NODES; i++) {int hash = getHash(ip+"VN" +i);public static String getServer (String clientInfo) int hash = getHash(clientInfo);if (nodeIndex == null ) {return virtualNodes.get(nodeIndex);private static int getHash (String str) final int p = 16777619 ;int hash = (int ) 2166136261L ;for (int i = 0 ; i < str.length(); i++) {13 ;7 ;3 ;17 ;5 ;if (hash < 0 ) {return hash;public static void main (String[] args) for (int i = 0 ; i< 20 ;i++){"userid" +i));